Harness Engineering实践-AI自动评测优化平台
Harness Engineering实践:AI自动评测优化平台
核心观点
本文介绍了一个AI First的自动化评测平台实践:定义评测任务后,AI自主生成评测集、模拟用户运行评测、生成报告,乃至基于报告优化系统并持续迭代。平台的核心设计理念是只允许AI操作,人无法操作——从入口层面杜绝人干苦力活。文章通过三个递进案例展示了从基础功能评测到UI内容质量评测再到全自动系统优化的完整路径。
平台架构
设计理念
传统评测:人定义任务→人收集评测集→人进行评测→人看结果。痛点:苦累、耗时、意愿低。
AI First评测:人只需描述评测目标→AI生成评测集→AI模拟用户运行→AI生成报告→AI基于报告优化→继续迭代。
平台能力
平台分不同工作空间,通过复制"技能说明"链接到本地Agent(Claude Code/Codex/QoderWork/悟空等),Agent即可操作:
- 创建评测任务:写明评测目标、验收标准
- 创建评测集:绑定评测任务,包含明确评测步骤和预期结果
- 创建评测报告:基于评测集的执行报告,含打分
评测集类型
两种类型:
- 标准型:有明确成功/失败状态
- Rubrics型:内容质量评测,无法简单成功失败,生成不同等级评测用例
例如评测"查询OKR"——不仅看查没查出来,还用rubrics生成不同等级用例评估质量层次。
案例一:基础全自动化评测(无UI)
场景:全方位测评钉钉文档MCP。
操作:在QoderWork中输入评测平台链接+任务描述("测试钉钉文档MCP,了解能做什么,发布评测任务,生成至少10个评测集,进行评测提交报告")。
结果:
- 自动创建评测任务"钉钉文档MCP工具全功能评测"
- 设计13个测试用例,覆盖MCP主要功能
- 用例具有连贯性(前后衔接)
- 总分95分,扣5分原因:"创建文件夹时名称被自动追加序号(1),接口未返回冲突提示"
- 完整评测报告3-4千字
案例二:带UI的自动化评测(含内容质量)
场景:评测"绘报"系统(输入文本/钉钉文档→生成精美汇报文稿PPT)。
操作:让QoderWork连接浏览器,共享登录态,自动打开系统进行分析。
能力扩展:
- 不仅评测功能是否正常
- 还评测UI品味和质量
- 评测AIGC生成内容质量
- Agent自己打开浏览器操作页面截屏对比
结果:5个PPT全部评测完成(约20分钟),整体85分,每个PPT有功能+质量双维度评测。
案例三:全自动系统优化(评测+优化循环)
场景:业务系统中两个AI功能,要求自动优化三轮。
操作:在Cursor中输入评测平台链接+"发任务→做评测集→评测→优化→再来一轮→至少三轮"。
过程:
- 每轮评测约1小时(AI功能需等系统跑完)
- 总共三四小时,人去睡觉
- Cursor等待评测集在系统上真实跑完,再评测,再基于报告修改代码优化
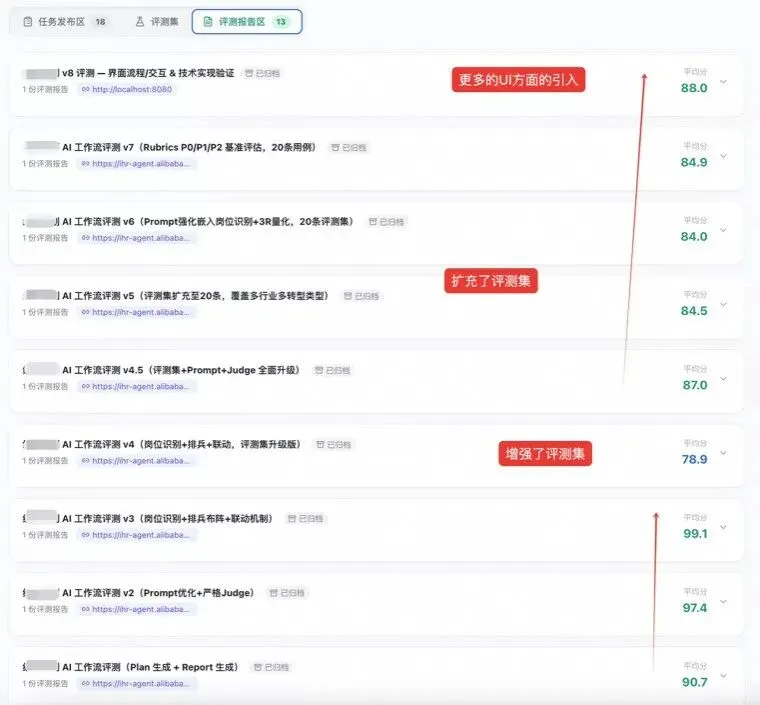
结果:
| 版本 | 分数 |
|---|---|
| v1 | 90.7 |
| v2 | 97.4 |
| v3 | 99.1 |
五个维度全面对比清晰,每个用例每个维度都有列表说明后才给评分。
先决条件
跑通全自动评测优化需满足:
- UI规范和基础设施达标:不规范导致AI在UI里"迷路"——AI都迷路了用户更会迷路,这本身就暴露了需要优化的基础问题
- 系统AI Coding含量高:人工系统约定大于配置内容太多,AI难以跑通功能和优化。跑得好的案例都是AI Coding含量高的系统,AI可快速启动本地服务做验证。老系统日常环境缺失、到处断头路则做不好
关键概念
关键引用
"平台AI First的理念——只允许AI操作,人无法操作,从入口层面杜绝人去干苦力活。"
"AI都迷路了,更何况用户呢。"
"这种模式也可以推广到:你有一个skill文件夹包,基于这个skill包去生成几百个评测用例,判断触发没触发效果怎么样,最后基于评测结果自动化优化skill包。"