告别氛围编程-Harness治理与SDD团队级AI研发实践
告别氛围编程:基于 Harness 治理和 SDD 的团队级 AI 研发范式演进与实践
核心观点
阿里高德大模型应用平台团队(王树新)分享了从"氛围编程"(Vibe Coding)到"规范驱动 + 工程治理"的团队级 AI 研发范式演进。这篇文章回答了一个关键问题:为什么 AI 出码率从 53% 暴涨到 80-90%,但项目交付周期没有明显缩短、开发者工作量没有减少?
答案是三个层面的深层困境,而解法是 SDD(Specification-Driven Development,规范驱动开发)+ Harness Engineering(驾驭工程)两套体系的结合,打通从需求 PRD 到部署的全流程自动化。
背景:从 53% 到 90% 的困惑
2025年9月云栖大会,团队分享了基于 Qoder 的研发提效实践,通过 Prompt 工程和上下文工程实现了 53% 的 AI 出码率。半年后出码率达到 80-90%:
"这个数字看起来非常漂亮,几乎翻了一倍。但当我们深入访谈团队、查看 PMO 的数据指标时,我们发现了一个令人困惑的事实:提效并不明显。"
"出码率提升了,但项目交付周期没有明显缩短;AI 写了更多代码,但开发者的工作量并没有减少。"
AI Coding 三大核心问题(初期识别)
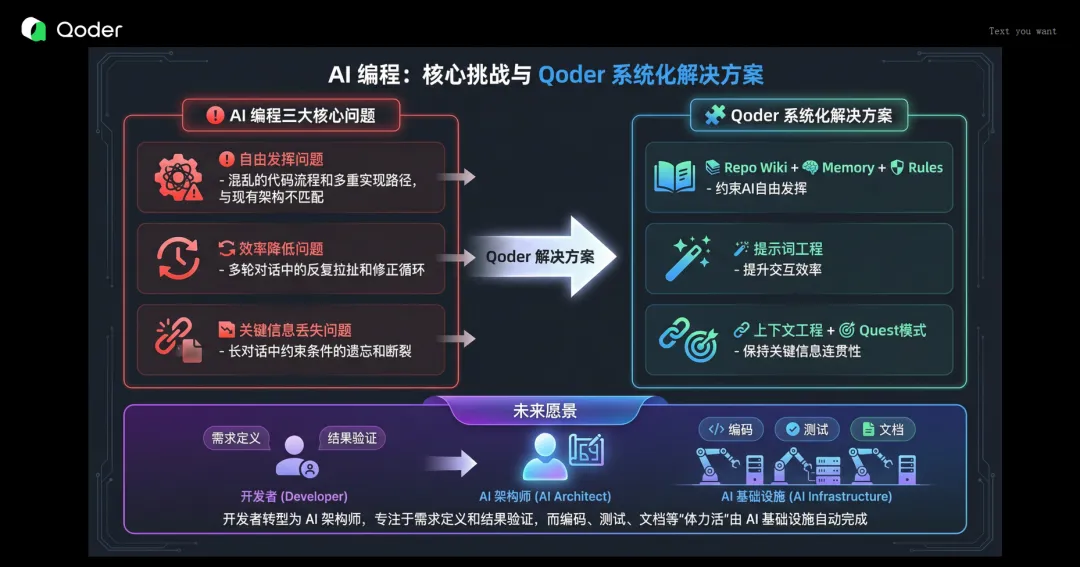
自由发挥问题:AI 生成代码天马行空,业务理解不足、规范缺失
"你让它写个功能,它可能给你三种不同的实现方式,每一种都'能跑',但每一种都可能和你现有的架构格格不入。"
效率降低问题:指令不清导致多轮对话反复拉扯
"你说'改一下',它改了;你说'不对,是这样',它又改了。来回几次,还不如自己写。"
关键信息丢失问题:多轮对话中 AI "忘记"之前的重要约束
"任务粒度过大时,开头说的架构要求,到后面就消失了。"
初期解法是通过 Repo Wiki、Memory、Rules 约束自由发挥;提示词工程改善效率;上下文工程和 Quest 模式避免信息丢失。
出码率 ≠ 提效的三个深层原因
原因 1:研发是全链路过程,不仅仅是写代码
完整链路:产品提需 → 产研评审 → 方案设计 → 开发 → 代码评审 → 测试 → 联调 → 上线。每个环节都有沟通成本、等待时间、出错可能。
"《人月神话》中有一个著名的理论——没有银弹。你把编码环节优化了 50%,但如果编码只占整个链路的 30%,那整体提效只有 15%。更何况,AI 生成的代码可能带来更多的 Code Review 时间,更多的调试时间,更多的返工时间。"
结论:真正的提效必须打通全链路,让 AI 跨越环节边界,从需求到部署形成闭环。
原因 2:存量应用 Vibe Coding 风险极高
"什么是 Vibe Coding?就是'氛围编程'——随口给 AI 几句提示词,让它几秒钟生成几千行代码。这种方式在新项目、小脚本上可能还行,但在存量应用中,风险极高。"
存量应用特点:有历史包袱、有隐式依赖、有业务知识沉淀在代码里。
"我们曾经遇到一个案例:AI 生成的代码修改了一个核心接口的参数顺序,单元测试全过了,但上线后导致三个下游服务报错。排查了整整一天。"
结论:在存量应用中,AI 编程必须从"氛围"走向"规范",必须有明确的验收标准。 这就是引入 SDD 的原因。
原因 3:大型项目超出单次 AI 对话能力边界
"我们遇到过这样的需求:一个涉及前后端十几个模块的重构任务。你不可能在一个对话里完成,AI 的上下文窗口有限,它的注意力也会分散。任务太大,AI 就会顾此失彼。"
三个原因指向同一个结论:
"AI 编程要从'个人技能'升级为'团队级工程能力',要从'氛围编程'进化为'规范驱动、工程治理'的研发范式。"
SDD(Specification-Driven Development,规范驱动开发)
核心颠覆
"SDD 的核心思想是颠覆性的:规范不再是写给人类看的散文,而是结构化的、可被 AI Agent 精确理解和执行的'意图代码'。"
在传统开发中,PRD 或设计文档只是"指导书",代码才是唯一的"真理之源",导致文档很快过期。SDD 颠覆了这个结构:
"规范成了唯一的真实来源。当需求变更时,开发者首先修改的是'规范',随后由 AI 工具根据规范重新生成、验证并更新底层代码。"
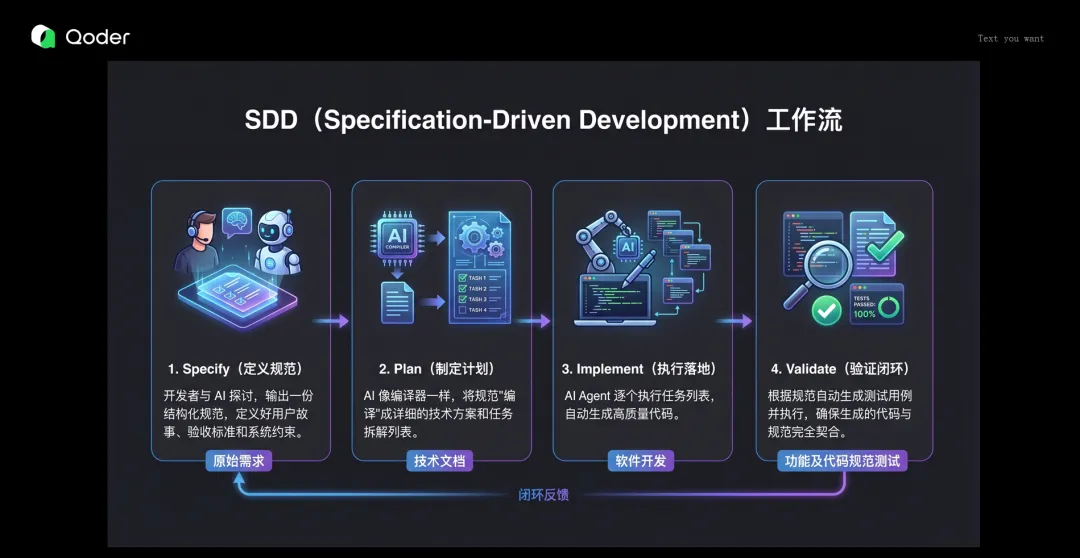
四阶段工作流
Specify(定义规范):开发者与 AI 探讨,输出结构化规范——用户故事、验收标准、系统约束。这是"原始需求"阶段。
Plan(制定计划):AI 像编译器一样将规范"编译"成详细技术方案和任务拆解列表。这是"技术文档"阶段。
Implement(执行落地):AI Agent 逐个执行任务列表,自动生成高质量代码。这是"软件开发"阶段。
Validate(验证闭环):根据规范自动生成测试用例并执行,确保生成代码与规范完全契合。这是"功能及代码规范测试"阶段。
SDD 的核心要求
- 规范中的验收标准必须可测试、无歧义
- 对比:"用户登录成功后跳转到首页"(模糊)vs "用户登录成功后,3 秒内跳转到首页,并在首页显示用户昵称"(可测试)
- 规范作为 AI 的"施工图纸",告别"氛围编程"
Harness Engineering(驾驭工程)
定位
"如果说 SDD 解决的是'做什么'的问题,Harness 解决的就是'如何可控地做'的问题。"
"想象一匹野马——AI 大模型拥有无穷的力量,但没有马具,你根本骑不上去,甚至可能被它甩下来。Harness Engineering 的核心,不是去改变马的基因(模型本身),而是为这匹野马设计一套精密的控制系统。"
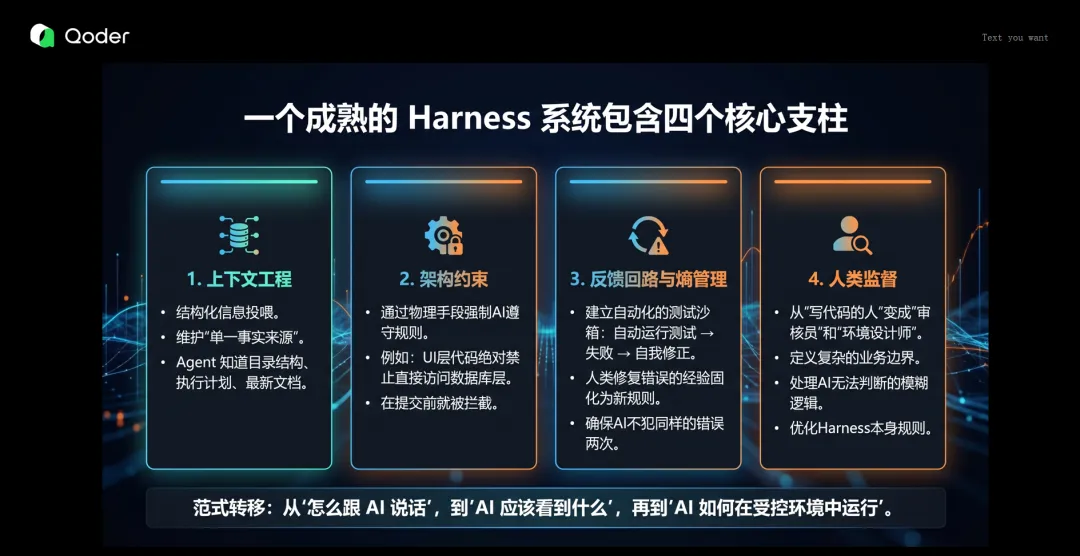
四个核心支柱
支柱一:上下文工程
不再是简单的 RAG,而是结构化信息投喂。维护"单一事实来源",让 Agent 知道项目的目录结构、当前执行计划、哪些文档最新。
支柱二:架构约束
"这是 Harness 最硬核的部分。通过物理手段强制 AI 遵守规则。例如,规定 UI 层的代码绝对禁止直接访问数据库层。如果 AI 试图违反架构分层,代码甚至无法通过语法检查,从而在提交前就被拦截。"
支柱三:反馈回路与熵管理
"AI 一定会犯错,关键在于如何发现并修正。建立自动化的测试沙箱:Agent 写完代码 → 自动运行测试 → 失败 → 读取错误日志 → 自我修正并重试。更重要的是,将人类修复错误的经验固化为新的规则,确保 AI 永远不会犯同样的错误两次。"
支柱四:人类监督
"人类从'写代码的人'变成了'审核员'和'环境设计师'。职责是定义复杂的业务边界,处理那 5% AI 无法判断的模糊逻辑,以及优化 Harness 本身的规则。"
范式转移路径
"从提示词工程到上下文工程,再到 Harness Engineering,这是一个范式转移:从'怎么跟 AI 说话',到'AI 应该看到什么',再到'AI 如何在受控环境中运行'。"
全流程自动化实践(Qoder 落地)
步骤 1:设计知识库(三层结构)
整个实践的基础。按项目层、技术层、资产层三层结构组织知识:
- 项目层:项目概述、目录结构、架构设计、技术选型。维护顶层 README.md 作为"单一事实来源"——如果某信息不在文档里,对 Qoder 来说它就不存在
- 技术层:通用技术知识、编码规范、中间件文档、三方库文档、最佳实践、常见问题解决方案。可跨项目复用,是团队技术沉淀
- 资产层:可复用代码片段、组件、模板、历史需求 PRD、技术方案、归档的测试 Case。团队多年积累的"砖块"
文档通过 README.md 索引实现按需加载。分层索引机制保证知识结构化,又实现按需灵活性,避免上下文过载。
Memory 机制:解决 AI 的"上下文焦虑"。在长周期项目开发中,AI 需要记住之前的决策、当前进度、待办事项。Memory 提供结构化方式存储和管理这些信息,让 AI 在正确上下文中做出正确决策,不是每次从零开始。
步骤 2:处理需求 PRD(HITL 人在回路)
使用 Qoder 的 Quest Spec 模式生成规范化 design.md。需要人工干预(HITL,Human-In-The-Loop)。
"为什么要 HITL?因为需求文档中有很多'隐性知识'——那些产品经理认为理所当然、但实际上需要澄清的信息。比如'用户登录'这个简单的功能,背后可能有:支持哪些登录方式?是否需要记住登录状态?密码强度有什么要求?登录失败怎么处理?"
通过 Spec 模式,AI 主动提问引导开发者澄清隐性知识,逐步补齐完整 Spec。输出包含:
- 数据模型:涉及哪些数据表、字段定义、关系
- 接口规范:API 输入输出、错误码、幂等性要求
- 验收标准:可测试、无歧义的标准
步骤 3:专家团执行(Experts Mode)
Spec 准备好后进入执行阶段,使用 Qoder 专家团模式。
"专家团模式的核心思想是:不同的任务由不同角色的 Agent 来完成。就像一个真实的开发团队,有前端工程师、后端工程师、测试工程师、架构师等角色。"
AI 根据 Spec 生成执行计划,把大型任务拆解成可管理的小任务,每个小任务有明确的输入、输出和验收标准。系统内置五类专家,每类专家有独立工具集,还支持自定义专家类型。
用户角色转变:
"用户也是协调链路的一部分。你可以在专家团运行时随时介入,Experts Leader 在下一轮循环中处理,调整任务方向或取消不再需要的任务。你的角色变了:和 Experts Leader 澄清意图、对齐方向、审核计划、验收结果,更像带一个有经验的研发小组。"
步骤 4:任务部署(MCP 打通 CI/CD)
通过 Aone(阿里内部 CI/CD 平台)的 MCP(协议) 工具,将构建产物交付给运维 Agent 部署。运维 Agent 可以:触发 CI/CD 流水线、执行部署脚本、查询部署状态、处理部署异常。
Skills 扩展:Qoder 的能力扩展机制,AI 获得额外能力如数据库操作 Skill——直接查询和修改数据库进行数据准备和验证。
总结:角色转变
"开发者不再是被动的代码编写者,而是主动的需求定义者、规范审核者、结果验证者。AI 不再是不可控的黑盒,而是在 Harness 约束下的可靠工具。"
未来三方向
- 更智能的 Spec 生成:当前需较多人工干预,未来通过更智能的对话式需求澄清降低人工成本
- 更强大的 Agent Teams:探索更复杂协作模式(多轮迭代、动态角色分配)
- 更完善的知识管理:更智能的知识提取、知识更新、知识复用机制
与 wiki 其他内容的关系
本文是 Harness Engineering 在大厂(阿里高德)的完整落地案例,与 wiki 中其他 Harness 文章形成互补:
- 补充了 SDD 规范驱动开发的完整工作流定义和落地细节
- 提供了**"出码率 ≠ 提效"的实证数据**(53% → 90% 但交付周期无缩短)
- 给出了存量应用 Vibe Coding 风险的真实事故案例
- 展示了知识库三层结构的企业级实操设计
- 演示了从需求到部署全链路自动化的完整实践路径
关键引用
"出码率提升了,但项目交付周期没有明显缩短;AI 写了更多代码,但开发者的工作量并没有减少。"
"在存量应用中,AI 编程必须从'氛围'走向'规范',必须有明确的验收标准。"
"规范不再是写给人类看的散文,而是结构化的、可被 AI Agent 精确理解和执行的'意图代码'。"
"从提示词工程到上下文工程,再到 Harness Engineering,这是一个范式转移:从'怎么跟 AI 说话',到'AI 应该看到什么',再到'AI 如何在受控环境中运行'。"